こんにちは。You’re a software engineer and want to learn Japanese? Or you’re just someone who wants to optimize the hell out of anything? Well then this post is for you — I’ll share my workflow for learning Japanese, and how I integrate software engineering practices into the process to make it more efficient!
Info
This is not a “How to get started learning Japanese” guide; Rather, it’s a snapshot of my personal learning journey, which I hope will kickstart or enhance your own.
Introduction over, let’s get straight to the point; my workflow consists of four main pillars:
📺 Immersion
Immersion is the process of surrounding oneself with the target language through various forms of media and interaction, such as watching videos, listening to music or engaging in conversations with native speakers.
Yes, I get it, immersion is hard — especially in the beginning. However, it’s also the most crucial part for naturally understanding and learning a language. After all, language is a tool for communication. If you don’t use it as such, and instead lose yourself studying its abstract structure (= grammar), you will be less efficient and have less fun.
The right content
The best content for immersion is the one you almost understand, but not completely — also known as comprehensible input or n+1 content. As a beginner, rather than getting frustrated with Japanese anime you can’t follow, start with material you mostly grasp but still find challenging. It’s crucial that this content interests you; otherwise, you’ll lose motivation and stop engaging with it. Since the best content varies based on language, proficiency, and personal interests, there’s no generic recommendations I can give. However, you can easily find good resources that float your boat, by searching for the following query using the search engine of choice:
comprehensible input for <target_language> (<level>); reddit
Finally, if you’re studying Japanese, these are some of my favorites:
| Name | Type | Level |
|---|---|---|
| Comprehensible Japanese | Video | N5-N1 |
| Yuyuの日本語 Podcast | Audio | N4-N3 |
| NHK News Easy | Text | N4-N3 |
Yomitan
Immersion should feel immersive (duh). Therefore, you should avoid interruptions such as looking up words or translating sentences. Not understanding every word/sentence is okay — it may not feel like it at the moment, but you’re still learning from it.
That being said, there is however one tool that I often use when doing text immersion: Yomitan. Yomitan is a browser extension, that enables you to hover over any word and see its meaning, reading pronunciation etc.:

Simply being able to hover Japanese words on the internet to understand them, has made it an invaluable tool for me. Furthermore, combined with subtitles, it’s also useful for understanding videos or podcasts better. There’s also another killer feature Yomitan offers, which I will discuss soon…
📖 Vocabulary
Cramming vocab is what most people associate with learning a new language. And indeed, there’s no way around it. However, you can optimize it — with the power of some code!
Anki
First off, you will need a flashcard application. I strongly recommend Anki, since it’s the most popular and flexible one out there. Anki allows you to create decks, which contain flashcards that you can review. In its most basic form, a flashcard consists of two sides, which you can flip over to reveal e.g., a words’ translation:
What makes Anki so powerful is its extensive plugin system and community support. For example, there are tons customisations or addons to reduce your suffering while reviewing cards. Furthermore, Anki also lets you import decks other users created. However, for studying vocabulary, I would not recommend using such pre-made decks, since what you actually want to do is creating your own flashcards from words you encountered during immersion. That way, you will actually have a need to know the word, which makes remembering and using it correctly a lot easier.
Deck structure
I have two vocabulary decks: an inbox and a main deck. The inbox holds cards that aren’t fully completed yet, while the main deck contains all the ready cards that I actively review.

Creating flashcards
So how can you efficiently create flashcards? When I first started using Anki, I quickly got frustrated with how time-consuming the process was: To create a single flashcard, I needed to fill out all the following fields of my template:
- Word (Japanese)
- Translation (German)
- Translation (English)
- Example sentence
- Pronunciation-clip
- Image
- Word Constituents
- …
That’s horrible — right! I almost resorted to using the generic pre-made decks mentioned earlier, but then an old friend came to my rescue…
Yomitan (again)
As it turns out, Yomitan is not only useful for looking up words you don’t know, but also creating custom Anki flashcards from them — with the click of a button:

Furthermore, this Anki integration is fully customizable. It let’s you specify how to fill the different fields of your cards, which tags to add, and more:
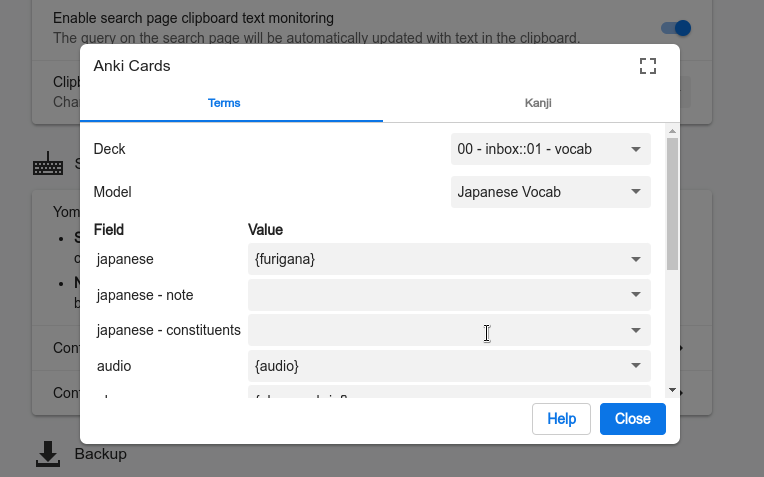
For a full setup guide, you can check out the official documentation.
Anki-Patcher
Anki + Yomitan is a great combination for quickly creating new flashcards. However, I still wasn’t satisfied, since some fields of my template were still blank:
- Image
- Word Constituents
- … (other complex fields)
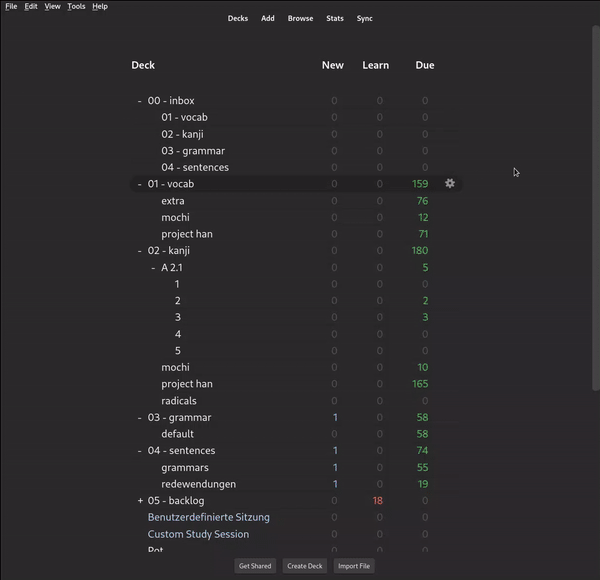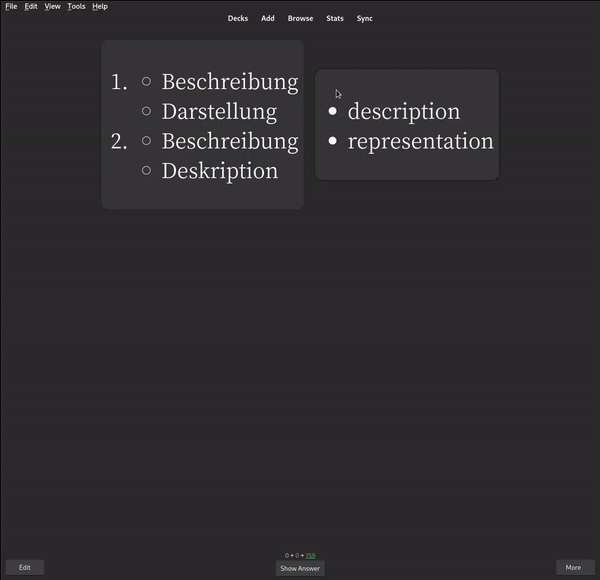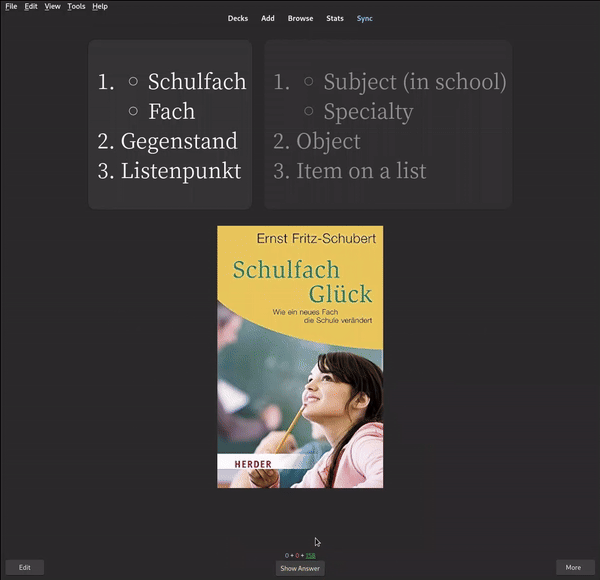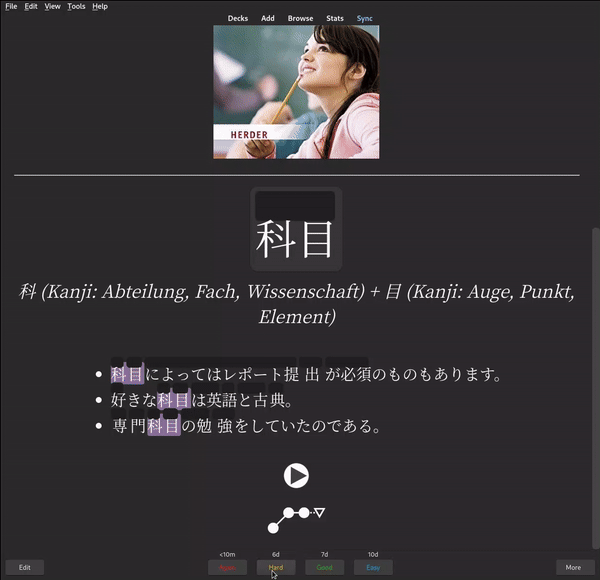
Let’s take word constituents for an example: In Japanese, most words consist of kanji characters, each of which has its own meaning. For example, the word 昼寝 consists of 昼 (daytime) and 寝 (lie down). As you can probably guess now, 昼寝 means nap in English. To remember words, I find this information extremely useful. However, adding such complex information to flashcards is nothing that Yomitan could easily do.
Anki-Patcher is a tool I created to solve this problem. At its core, it is simply a script launcher, that can manipulate Anki flashcards. Here’s how it works:
- choose one of the existing operations or write your own by implementing an interface
- define a configuration file, that specifies the operation further
- run
anki-patcherand see your cards getting updated
For example, to add the word constituents to my cards, I used my gpt
operation and provided the following configuration file:
input_field_names: the names of the fields on your card
- japanese
- glossary
prompt_template: "If the word (Japanese) consists of multiple components, explain the individual parts. Components can include Kanji characters, Hiragana, or grammatical elements. Distinguish between Kanji characters and words. Word: '{japanese}' ({glossary}) Components:"
output_field_name: "japanese - constituents" field to write the output to
do_overwrite_output: false whether or not to override it
model_type: gpt-4This configuration will take the flashcard fields japanese and glossary as an input, send a templated prompt to the OpenAI API, and write the response to the field japanese - constituents defined in output_field_name — boom there’s my field filled out automatically!
Over the past months, I have create a bunch of other operations such as e.g. add_image, add_example, swap_fields just to name a few. I use anki-patcher daily to refactor existing cards, or to continually integrate new flashcards from my inbox into my main deck:
#! /bin/bash
process-vocab-inbox.sh
VOCAB_INBOX="00 - inbox::01 - vocab"
echo "Processing $VOCAB_INBOX"
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )"
1. main processing
trim lists with more than x items
poetry run anki-patcher -o trim_list_items -c "$SCRIPT_DIR/../configs/trim_list_items_default.yml" -d "$VOCAB_INBOX" patch-async
add TTS if not exists
poetry run anki-patcher -o add_tts -c "$SCRIPT_DIR/../configs/add_tts_default.yml" -d "$VOCAB_INBOX" patch-async
add image if not exists
poetry run anki-patcher -o add_image -c "$SCRIPT_DIR/../configs/add_image_vocab.yml" -d "$VOCAB_INBOX" patch-async
add example if not exists
poetry run anki-patcher -o add_example -c "$SCRIPT_DIR/../configs/add_example.yml" -d "$VOCAB_INBOX" patch-async
add kanji constituents
poetry run anki-patcher -o gpt -c "$SCRIPT_DIR/../configs/gpt_constituents_vocab.yml" -d "$VOCAB_INBOX" patch-async
translate to english
poetry run anki-patcher -o gpt -c "$SCRIPT_DIR/../configs/gpt_translate_to_eng.yml" -d "$VOCAB_INBOX" patch-async
2. finally, some cleanups
remove some empty lines
poetry run anki-patcher -o replace -c "$SCRIPT_DIR/../configs/replace_english_empty_line.yml" -d "$VOCAB_INBOX" patch-async
add furigana to sentences
poetry run anki-patcher -o add_furigana -c "$SCRIPT_DIR/../configs/add_furigana_vocab_sentence.yml" -d "$VOCAB_INBOX" patch-async
echo "Done processing $VOCAB_INBOX"📜 Grammar
As mentioned earlier, I’m not a big fan of studying grammar in a vacuum. That being said, studying grammar can be an extremely efficient method to learn a language — if done right.

First, let go of the notion that grammatical rules are absolute truths. Natural language was not built on grammatical rules. Instead, it evolved organically as a means of communication — the rules followed afterward. So instead of thinking of them as cornerstones, on which a language was constructed on, try to think of them as mere learning aids for explaining syntax.
The second important point on grammar, which I want to share with you, is the fact that languages are taught differently, based on the speaker’s native language. For example, most Japanese textbooks written for Westerners contain vastly different grammatical rules than textbooks used by actual Japanese students. The assumptions of such textbooks is, that it is easier, for your lets say German mind, to understand Japanese grammar, if it is explained using concepts you are already familiar with: Verbs, Adjectives, Conjugations etc.
The problem, however, is that it’s bullshit: It does not scale. While it might give you a head start, since you can relate new concepts to ones you already know, it will hinder your progress in the long run. For example, you will eventually have to learn exceptions to those “rules”. Little will you know, however, that these exceptions only exist because the rule you learned was bullshit all along. Learning actual Japanese grammar might be difficult in the beginning, since resources are hard to find and many concepts will be new to you. However, it is also really eye-opening and most importantly more efficient - in the long run.
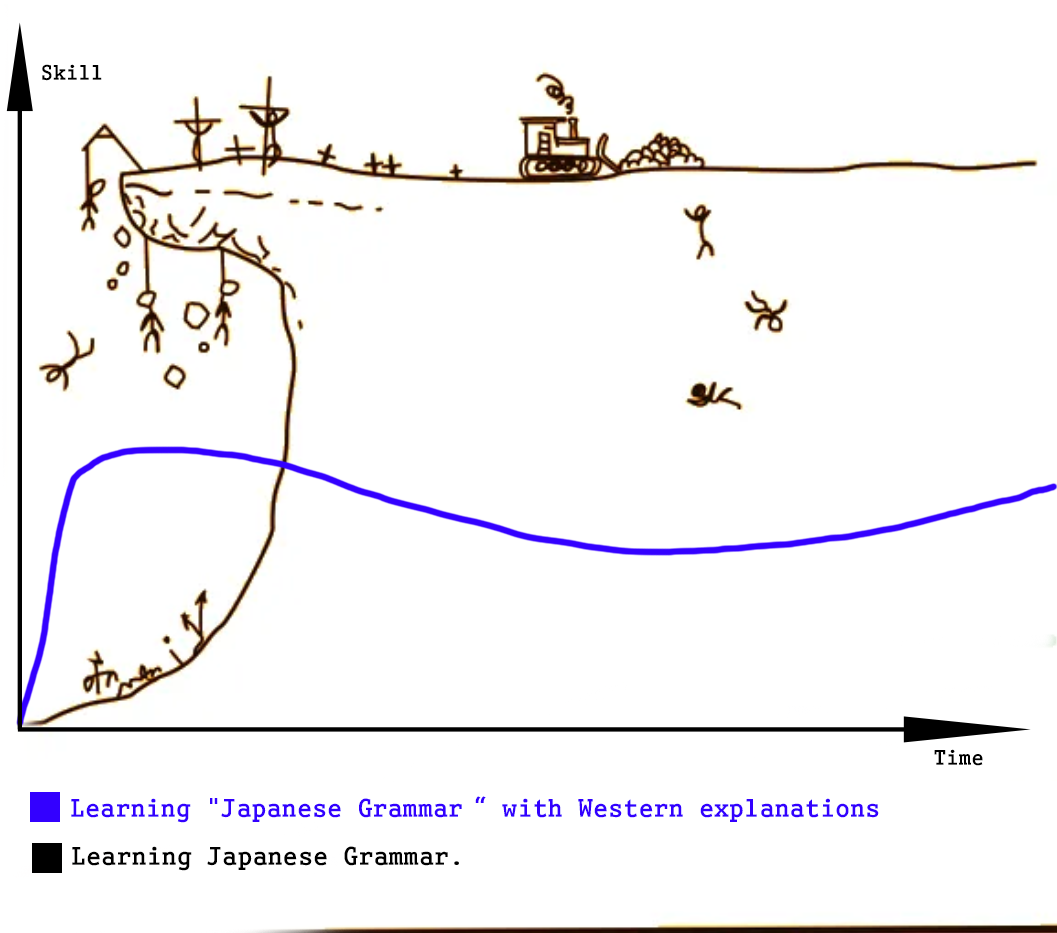
Cure Dolly
Finding sources for learning actual Japanese grammar is tough. Getting a Japanese textbook also isn’t an option in the beginning — it’s a chicken-and-egg problem.
Enter Cure Dolly, a YouTube channel that breaks down Japanese grammar fundamentally, without relying on Western grammatical rules for crooked explanations. There’s also a text version created by the community. I copied it into my Obsidian Vault (→ Cure Dolly Transscripts) and use it as my grammar bible ever since.
Obsidian
For taking notes, I use Obsidian. It’s free to use, and basically a frontend for managing and editing markdown files. In a sense, it’s similar to Anki, as it allows users to write their own themes and plugins to extend the app.
Obsidian Copilot
Obsidian Copilot is a community plugin, that i.e. provides a chat sidebar. :
It’s killer feature, is the Vault QA mode, which provides a RAG chat based on all of your Obsidian notes.
Info
RAG stands for Retrieval-Augmented Generation, a technique for enhancing the accuracy and reliability of generative AI models by dynamically fetching facts from external sources.
In my case, the external source is my Obsidian Vault, which includes grammar notes and Cure Dolly transcripts in plain text. Using Obsidian Copilot, I can easily query those sources in natural language. For instance, if I want to understand the Japanese Passive Receptive form, I can simply ask:
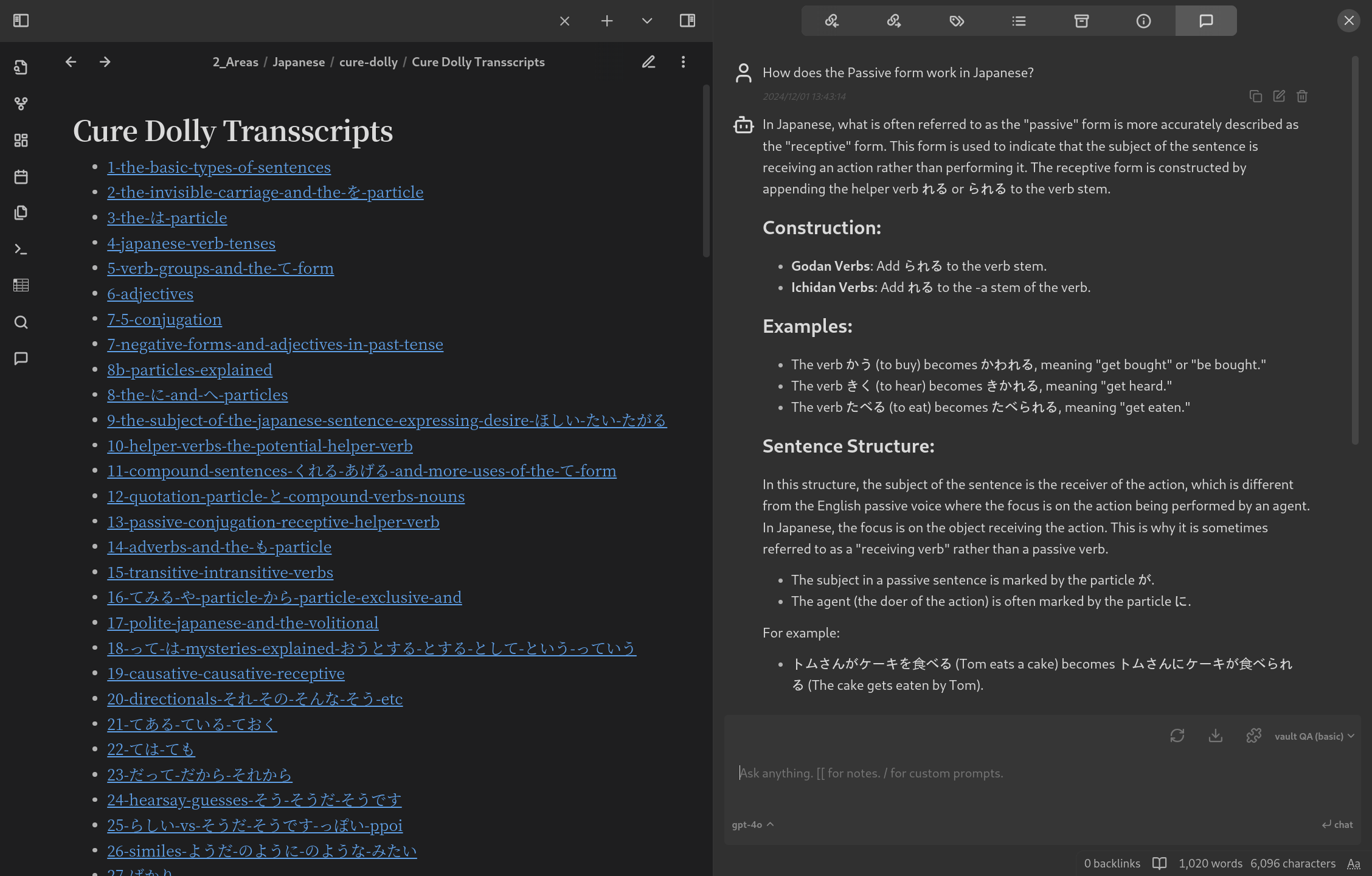
Since it’s a RAG chat, responses are drawn solely from my notes. I found this feature invaluable to 1. refresh on knowledge I already learned and 2. quickly learn about new concepts based on Cure Dolly information. Without it, I would have to manually search through all my notes and transcripts — that’s obviously inefficient.
㊗️ Kanji
Finally, there’s kanji. Similar to grammar, I’m not a big fan of learning them in isolation. While there are countless online lists detailing every kanji’s meanings and readings, simply trying to learn those lists didn’t work for me. Instead, my process looks as follows:
- every Sunday, I pull 20 new Kanji cards from my Backlog into my Kanji deck
- every day, I review the Kanji deck
- whenever one of the new Kanji cards pops up, I look up words for each of its readings and add them to my vocab deck (e.g. 幹 →
幹 (= trunk)、新幹線 (= Shinkansen))
This dual-deck method helps me learn kanji effectively. In the Kanji deck, I focus on meanings, while in the Vocab deck, I ensure I get the readings right. This process not only simplifies kanji learning but also introduces me to interesting new words!
Obsidian (again)
While Anki is excellent for memorization through spaced repetition, Obsidian excels at linking and understanding concepts. I love links, and that got me thinking: Since Kanji often consist of other Kanji (= Radicals), what if I created notes for each Kanji, and link them all together based on how they constitute each other?
Sounds complicated? It’s not — here’s an example:
- (Know that the kanji ’休’ [to rest] consists of ’人‘[person] and ’木‘[tree])
- Create a note ’休.md’
- Create two notes ’人.md’ and ’木.md’
- Create links between ’休.md’→ ’人.md’ and ’休.md’→’木.md’ to depict the “consists of” relations
- Visualize the whole structure via Obsidians Graph-View
I thought, his visualization would help me in grasping relationships, understanding their components, and identifying key kanji (= kanji with many links). So I built it — in 30 minutes. This it what it looks like:
The creation process went as follows:
- Import the following decks into Anki:
- (create an Obsidian Vault)
- Export the deck to md files using anki-patcher via the
export_mdoperation and the following configs: - Use Obsidian Note Linker (another Plugin I built a while ago, albeit for a different purpose) to link together all Kanji/Radicals
The whole process consisted of mostly waiting. If you don’t want to wait and/or are too lazy to do it yourself, you can download the Vault from GitHub or see it live in action by clicking#kanji or#radical! Finally, you can also expand the vault yourself. For example, you can export your own vocab flashcards in the same manner and create links between them and kanji. Enjoy!
🏁 Summary
In this post, I went over how I do 📺 Immersion to practice Japanese, create and review 📖 Vocabulary using Anki, how I learn 📜 Grammar, and finally how I study ㊗️ Kanji with Obsidian.
If you have any tips yourself, feel free to share them wherever you found this post or contact me directly (💬 About & Contact)!