My current side project has no main.js. No entry point. The closest thing to a source file is a markdown document called CLAUDE.md that describes, in English, what the program does and how the parts fit together. Skills define how to do it, and MCPs/CLIs connect the whole thing to other systems.
There’s a name forming for this on Twitter: agent-native software, AI-native software, Software 3.0. The naming hasn’t settled. But the pattern is slowly forming; and it’s surprisingly similar to traditional software.
The four-layer stack
If you’ve written object-oriented code, the shape is familiar: a main() boots the program and calls into classes, classes expose methods, methods call out to SDKs for the actual I/O. Four layers, scope narrowing as you go down.
Agent-native software has the same four layers. Just different names:
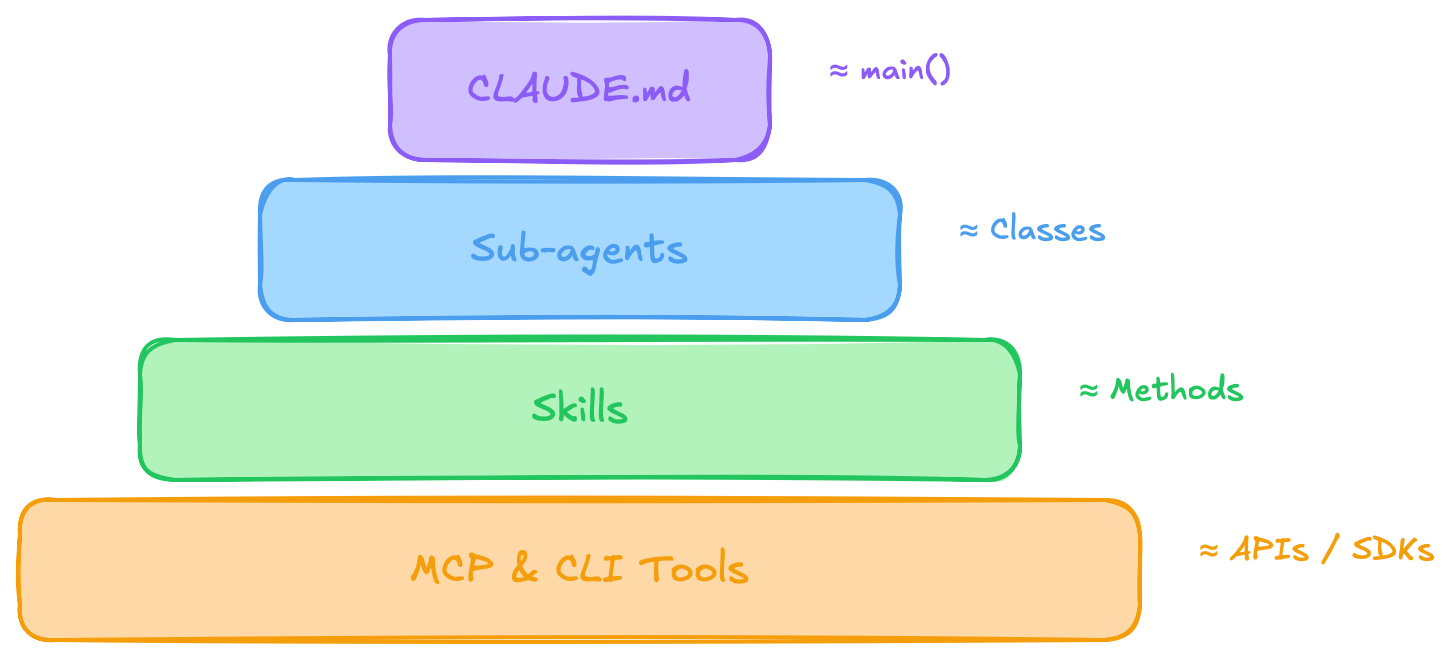
The orchestrator does no real work. It reads CLAUDE.md, figures out which sub-agent to call, and delegates.
Sub-agents are scoped: they get a description (main logic), a list of skills they can call (methods), and a permission scope (which CLIs / MCPs they’re allowed to touch). Most sub-agents don’t need bash. So they don’t get bash. The principle of least privilege, but enforced by what amounts to the class declaration.
Skills are the methods. Each one is a markdown file describing a procedure: given input X, do Y, return Z. The agent reads it when relevant, the same way you’d look up a method signature.
MCPs and CLIs are the SDK layer. Connectors to the outside world: the database, the calendar, the GitHub repo. From the program’s perspective, that’s where I/O happens.
State? Wherever you want. A SQLite file, a JSON, the filesystem. Nothing exotic.
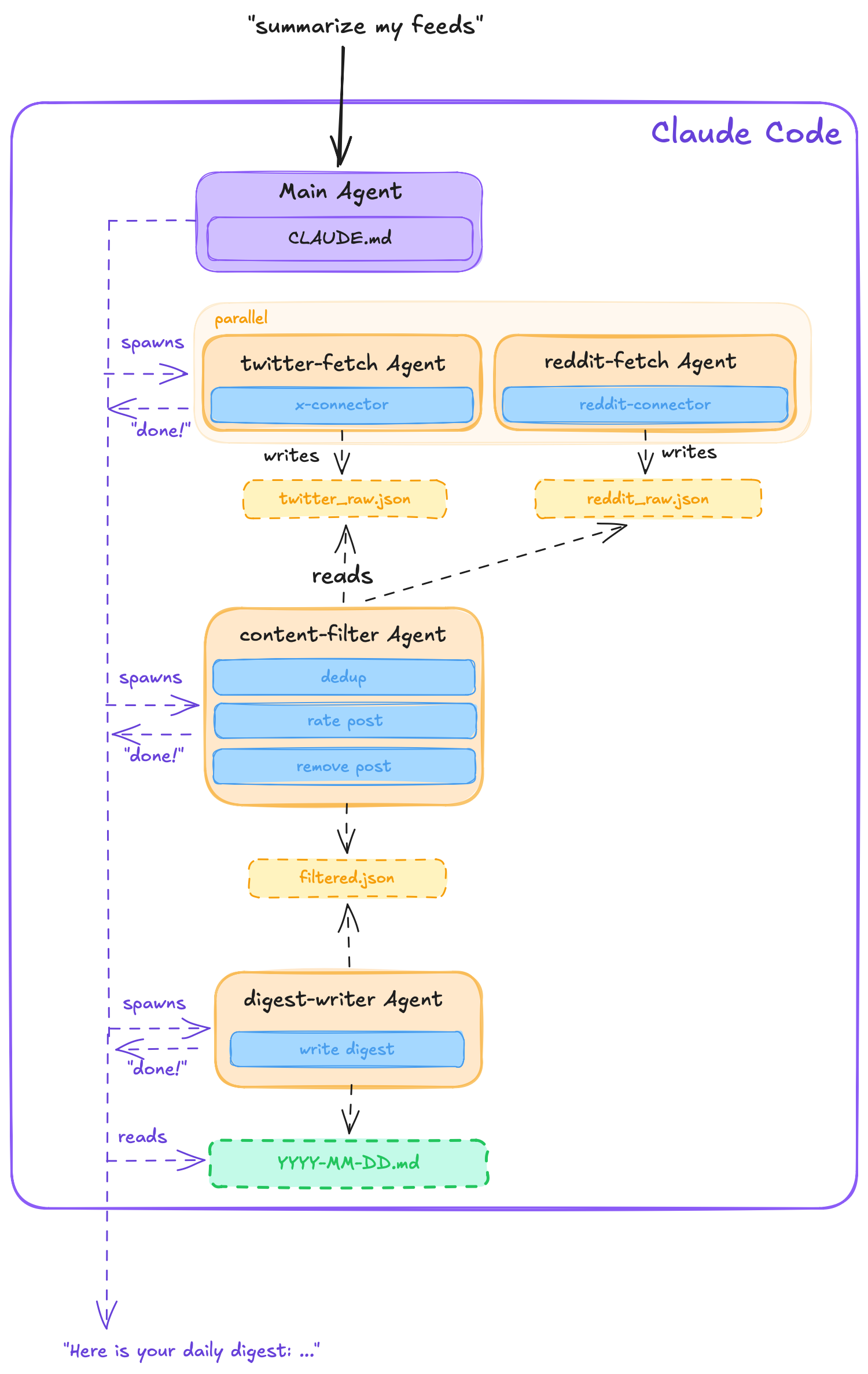
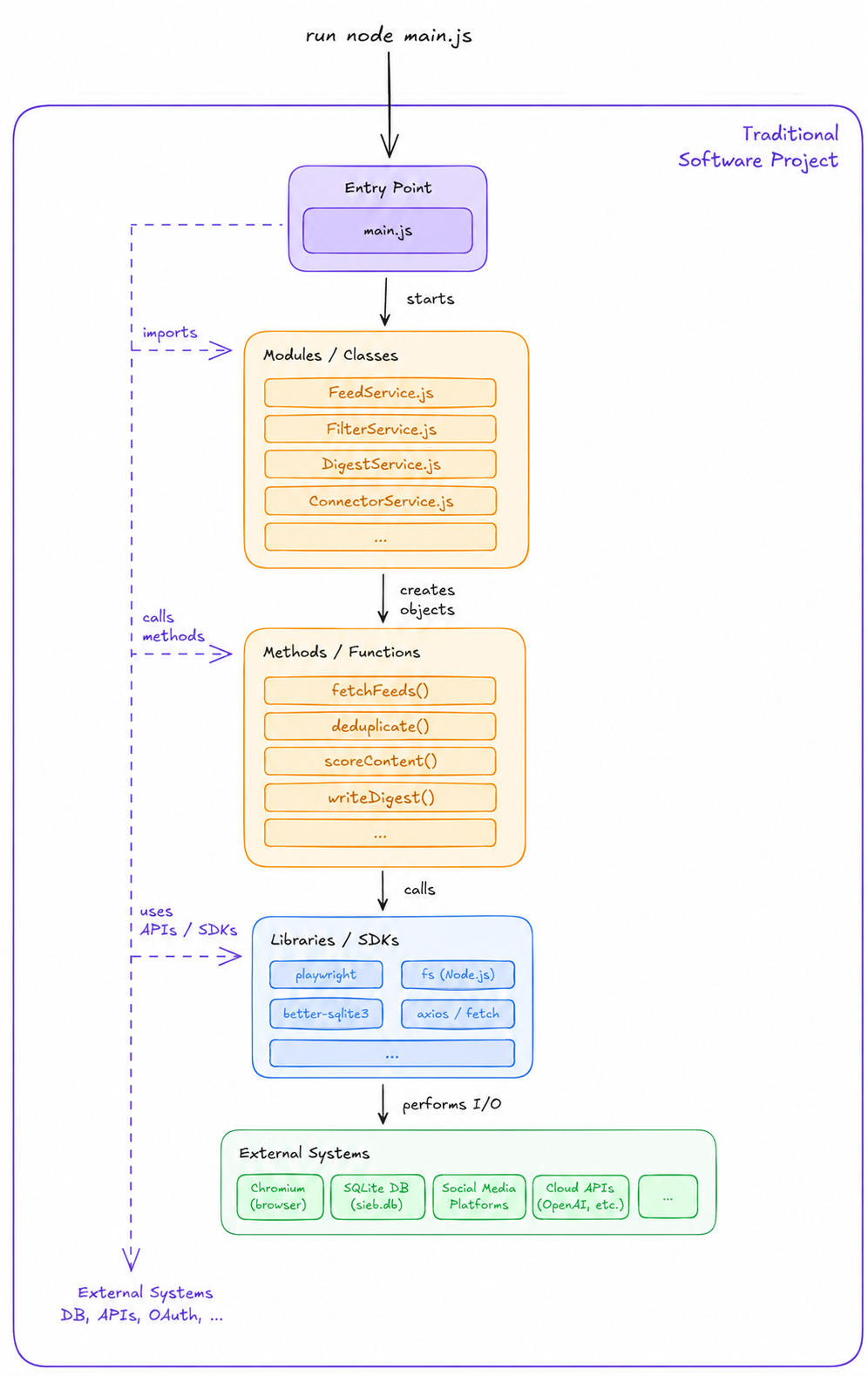
Here’s a concrete example: I was tired of doomscrolling Twitter and Reddit but still wanted to keep up. So I built a tool that scrapes my feeds, filters out the noise with LLM scoring, and hands me a daily digest. Left is the agent-native architecture, right is how you’d implement it in traditional OOP:
The software isn’t immutable
Here’s the part that’s strange.
Traditional software is immutable. You find a bug, you write a fix, you cut a release. There’s a changelog, a version number, a rollback plan.
Agent-native software isn’t.
If a skill breaks - e.g. an MCP changed its tool names and a skill is still documenting the old ones - you don’t have to ship a patch. Instead, you can have a heal agent, which automatically gets spawned and fixes any broken skills if errors occur.
I’m not sure if this is good or bad. Immutability is one of the load-bearing assumptions of how we ship software. None of that fits cleanly when the program can rewrite itself.
But it does mean the software is self-healing in a sense we haven’t really had before. It’s very interesting to use and I’ve often caught myself being stuck in the old, immutable, way of thinking until I realized: “Well, I can just tell Claude to fix this”.
The context window is the RAM
Back in the day, when machines had kilobytes of RAM, you thought very carefully about what to keep in memory. You passed pointers, not payloads. You freed what you didn’t need. Then RAM got cheap and big, and most of us stopped thinking about it.
The context window brings that problem back. It’s finite, it’s expensive per token, and if you stuff too much into it the model gets slow and confused. Working memory matters again.
This is where the modular architecture pays off. The orchestrator stays thin: it delegates and has the overview. Each sub-agent spins up with only its skill files and inputs, does its job, and dies.
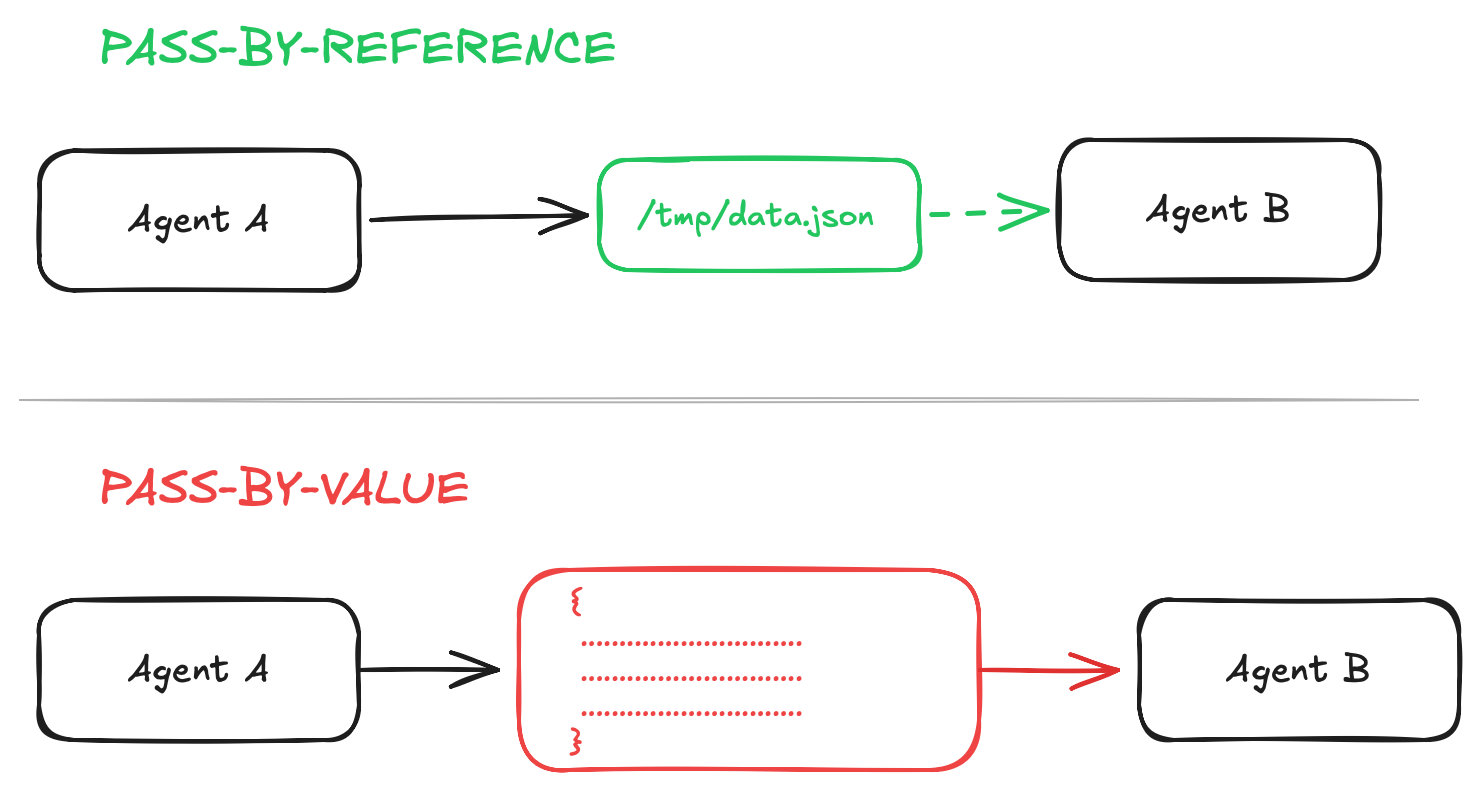
Concretely, this means: don’t pass results between agents by value. Don’t shove the output of one agent into the prompt of the next. Instead, write to temp files and pass the path. Essentially, it’s pass-by-reference vs. pass-by-value, and the tradeoff is exactly what it always was: reading on demand is cheap, copying is expensive. Same lesson, sixty years later.
Debugging is profiling sub-agents
In AI native software, you don’t profile functions; you profile sub-agents. The question isn’t “which function is inefficient?”; it’s “which sub-agent is having a hard time completing its task?”
Interestingly, it’s almost never that the work is hard. Instead, it’s that the description in an agent or skill file is leading down a road that doesn’t quite work, making the agent flail politely until it lands somewhere acceptable.
Essentially, the agent’s chain of thought and tool calls are your logs. If something’s off, you have to analyze them, and find out where the agent gets stuck. You can even ask the agent itself whats wrong! (One caveat: Anthropic keeps making the thinking traces harder to inspect, which is concerning. It’s the only instrument we have.)
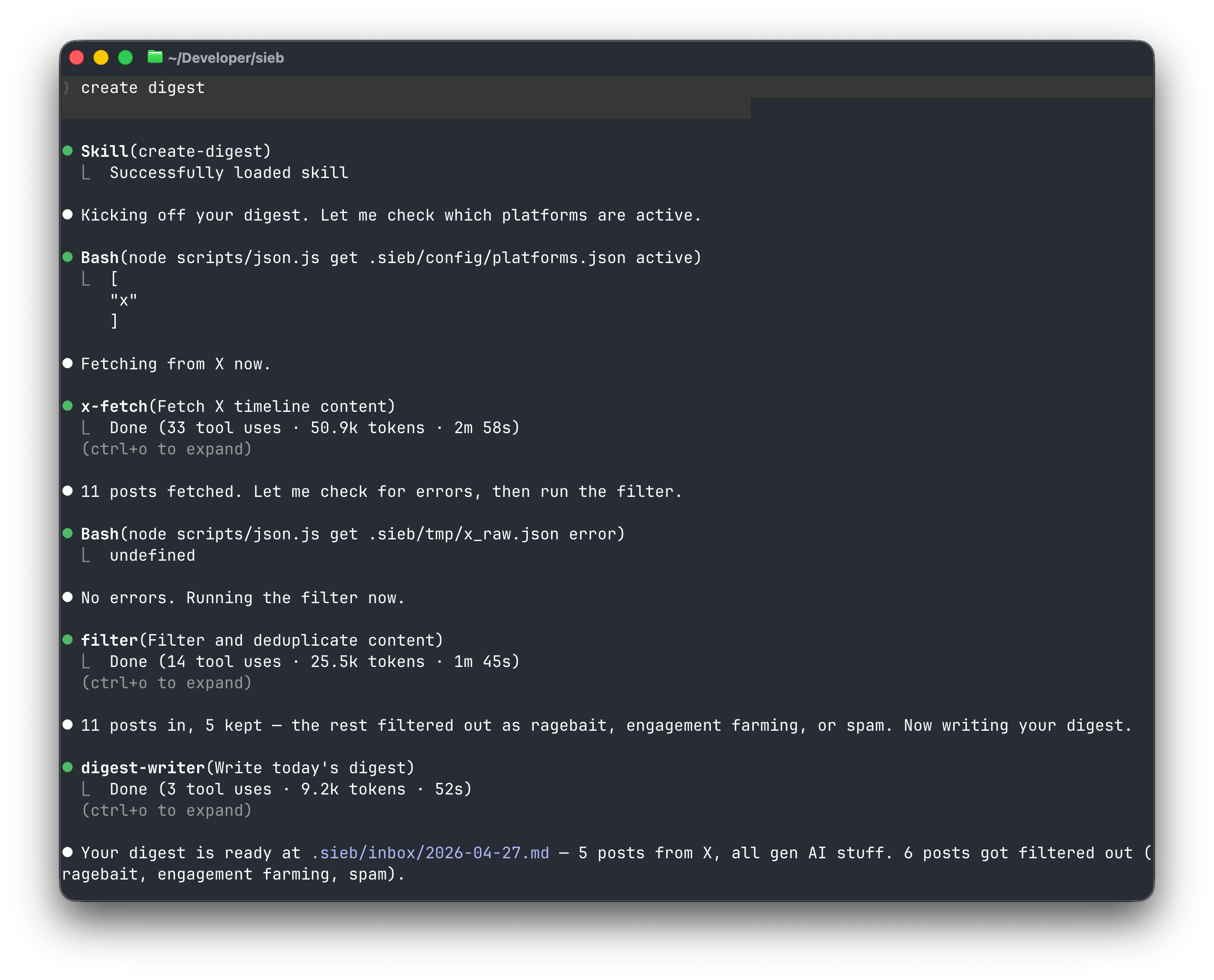
The UX is from 1985
There is no UI. You type slash commands into a terminal. There’s a setup script that runs once. Helper skills and user-facing skills sit in the same list, which is noisy. It’s awkward.
You can build a frontend on top of the Claude SDK if you want. I think people will. But the failure mode is ship the chat bar and call it a product, and that’s not the right shape here. I think the interesting UX direction is intent-based, not chat-based, but that’s a longer post.
What it’s waiting for
Two things: Speed and cost.
If the next generation of models is 20× faster and 20× cheaper at the same intelligence, this stops being a hobbyist pattern. Right now, we’re just early.
In the meantime: the architecture seems to be real, the analogies hold, and writing “software” like this is genuinely fun. It feels less like coding and more like designing a small organization.
And main.js? Doesn’t exist.
Source memos
- 2026-04-27-Agent-native software architecture — first half: layers, sub-agents-as-classes, self-healing.
- 2026-04-27-Debugging and speed for AI-native software — second half: debugging, context-as-RAM, speed/cost extrapolation.
Related
- 2026-06-14 — AI-native dev workflows at LBBW, CV-prep memo 3 (private) — workplace-scale evidence for this essay’s agent-native thesis. The DEBTVISION AI-team transformation lands the 80% AI-generated code survey number and the 2x story-point throughput trajectory after a ~2-month learning-curve dip — the agents-orchestrating-agents organization scaled across a whole dev team, not just a single power user.
- Alexander Weichart - Professional Experience (private) — long-form CV doc; the AI-Native Development Transformation cross-cut section is the structured form of the same claim made in this essay. Useful when this post needs a personal-experience companion in a CV-prep / interview context.
- 2026-07-08 — 10ten design call (private) — this essay’s pattern in casual practice: refactoring Claude is good at (the Ruby-columns cleanup), an Auto Ruby feature shipped as a Claude-built PR, and the Claude-annotation design workflow (later dropped for a call). The call was recorded via Monologue — the speech-to-text app named in this essay as an agent-native integration example.